


For the annual computer vision conference CVPR, Facebook is showing off an algorithm which can generate a fairly detailed 3D model of a clothed person from just one camera.
Facebook is the company behind the Oculus brand of virtual reality products. The company is considered a world leader in machine learning. Machine learning (ML) is at the core of the Oculus Quest and Rift S– both headsets have “inside-out” positional tracking, achieving sub-mm precision with no external base stations. On Quest, machine learning is even used to track the user’s hands without the need for controllers.
In a paper, called PIFuHD, three Facebook staff and a University of Southern California researcher propose a machine learning system for generating a high detail 3D representation of a person and their clothing from a single 1K image. No depth sensor or motion capture rig is required.
This paper is not the first work on generating 3D representations of a person from an image. Algorithms of this kind emerged in 2018 thanks to recent advances in computer vision.
In fact, the system Facebook is showing off is named PIFuHD after PIFu from last year, a project by researchers from various universities in California.
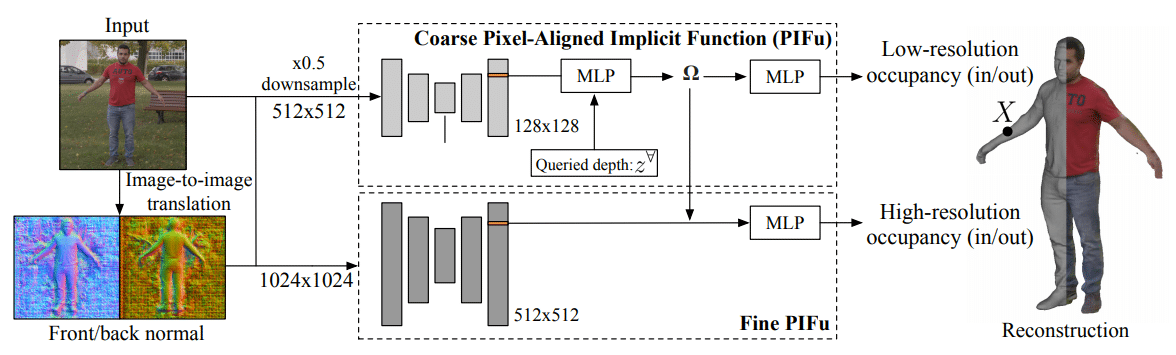
On today’s hardware, systems like PIFu can only handle relatively low resolution input images. This limits the accuracy and detail of the output model.
PIFuHD takes a new approach, downsampling the input image and feeding it to PIFu for the low detail “course” basis layer, then a new separate network uses the full resolution to add fine surface details.
Facebook claims the result is state of the art. Looking at the provided comparisons to similar systems, that seems to be true.

Facebook first showed off its interest in digitally recreating humans back in March 2019, showing off ‘Codec Avatars’. This project focused specifically on the head and face- and notably the avatar generation required an expensive scan of the user’s head with 132 cameras.
In May 2019, during its annual F8 conference, the company showed off real time markerless body tracking with unprecedented fidelity, using a model that takes into account the human muscular and skeletal systems.
Avatar body generation is another step on the path to the stated end goal; allowing users to exist as their real physical self in virtual environments, and to see friends as they really look too.
Don’t get too excited just yet- this kind of technology won’t be on your head next year. When presenting codec avatars, Facebook warned the technology was still “years away” for consumer products.
When it can be realized however, such a technology has tremendous potential. For most, telepresence today is still limited to grids of webcams on a 2D monitor. The ability to see photorealistic representations of others in true scale, fully tracked from real motion, could fundamentally change the need for face to face interaction.
























