




I recently wrote about what Lytro could theoretically do in VR with light field technology. Turns out that NextVR is getting into light fields too, but not necessarily in the same way.
(Warning: this is a pretty long read, the good jokes are somewhere near the end, and the really good information is somewhere in the middle. Happy hunting.)

“To be honest with you our plenoptic camera technology [read: light field],” says NextVR co-founder David Cole, “was totally area 51 until about a month, month and a half ago. The rig went out completely covered, you couldn’t see the constellation of light field cameras … [and] we were very, very, very careful” not to let anyone see it. “Then we said, at GDC, ‘let’s just blow a hole in this secret operation and have a bake sale.’ ”
So, did NextVR already do what I thought Lytro might, could, maybe do? Full-scale holographic imaging? Well, no. NextVR is using light field imaging as part of their depth-sensing algorithms. Cole again: “We’re using light field in maybe the the most pedestrian way you can, very fast, very accurate integration … [with data] we already get from stereopsis and depth from a very highly calibrated stereo rig.”
Let’s put this announcement in the proper context: it’s not really a light field announcement. NextVR is adding light field to their existing technology stack, so it’s just another piece of the puzzle. In other words: holographic? No. Important? Yeah. Sexy? Surprisingly so — for a ‘pedestrian’ application, the result is pretty awesome, in some ways better than holographic capture and display, and certainly different.
Virtual Cameras for Virtual Reality
To understand NextVR’s use of light field cameras, it’s important to understand what they’re doing and why. (Light field is just part of the ‘how,’ which we’ll get to later.)
First, the ‘what’: NextVR is interpolating every single pixel of their content on the fly, almost like a CGI render. If this seems counterintuitive (doesn’t a camera produce a perfectly good image already?) or downright wacky … you’re right. It’s a crazy way to do things, but it works perfectly for NextVR, a company with its roots in stereoscopic compression algorithms.
And the source material they’re using to interpolate those pixels are camera pixels, but camera pixels that are sort of bump-mapped in 3D space to reflect the true geometry of the world. Here are about 3,000 words as pictures to explain this quickly:
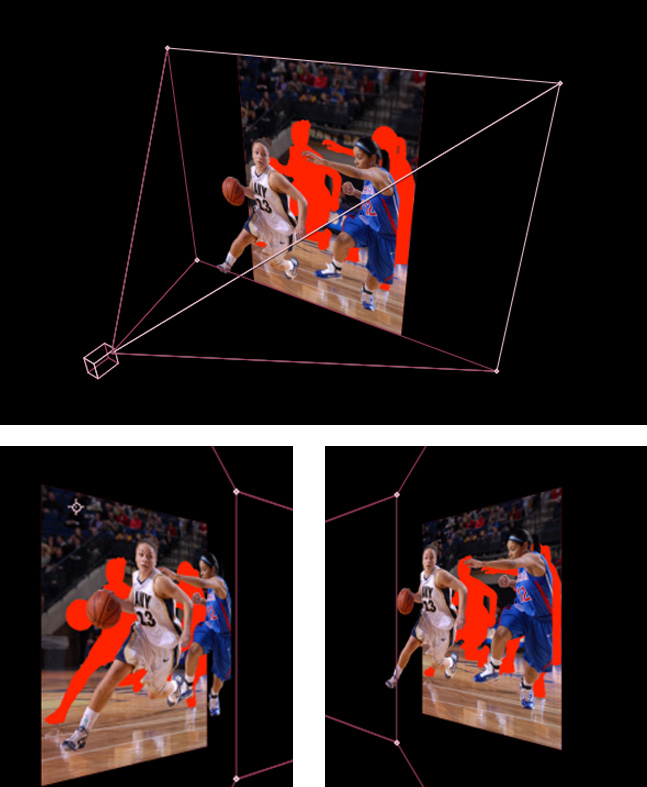
If that seems like a lot of work, you’re right. If it seems nearly impossible to do in realtime, you’re also right. So there’s got to be a really good reason to jump through all those hoops, right? The two reasons I can come up with are stitching and stereo-orthogonality. Let’s stitch first.
Seams are the Enemy of Good VR
If you’ve watched any second-tier live-action VR content, you’ve probably seen VR seams. They’re the disconcerting lines that stretch across your field of view, and sometimes have blurring or discontinuities in the image. It can look like a rip in the fabric of reality, but really it’s a natural consequence of real-world physics. Because to get 360 video, and especially 3D 360 video, you’ve got to have a bunch of cameras, and they can’t all occupy the same space. You can get them close — especially if your cameras are tiny, and your subject is far away. But unless they’re physically (or optically) in the same place, you’ll have seams in your image. And how you handle seams separates great VR content from the merely good (there are other things that would make VR content bad, like stabilization issues).
I’m particularly fond of the work of Felix & Paul, for example. They might be best known for “Strangers with Patrick Watson,” which played at Sundance, SXSW, Tribeca Film Festival, etc. It was also launch content on the GearVR (along with their Cirque du Soleil piece), which is how I experienced it. And all of their content I’ve seen shares a feature: great, seamless 360 degree 3D content. If you look at the piece very carefully, look all around, and maybe run some convolution filters on the image to find seams … you still won’t find them. It’s really well done. I believe (with no proof) they’re doing some very careful hand-work to eliminate the seams in their images.
Also, Parallax.
Seamless 3D video is not a trivial achievement. In fact, if you look carefully at the left and right eye views in F&P’s video, like running a difference map on the two views — not that I’m obsessed, but I have done this — you’ll see that the parallax on everything is also very consistent. This is why that’s hard to do in-camera:
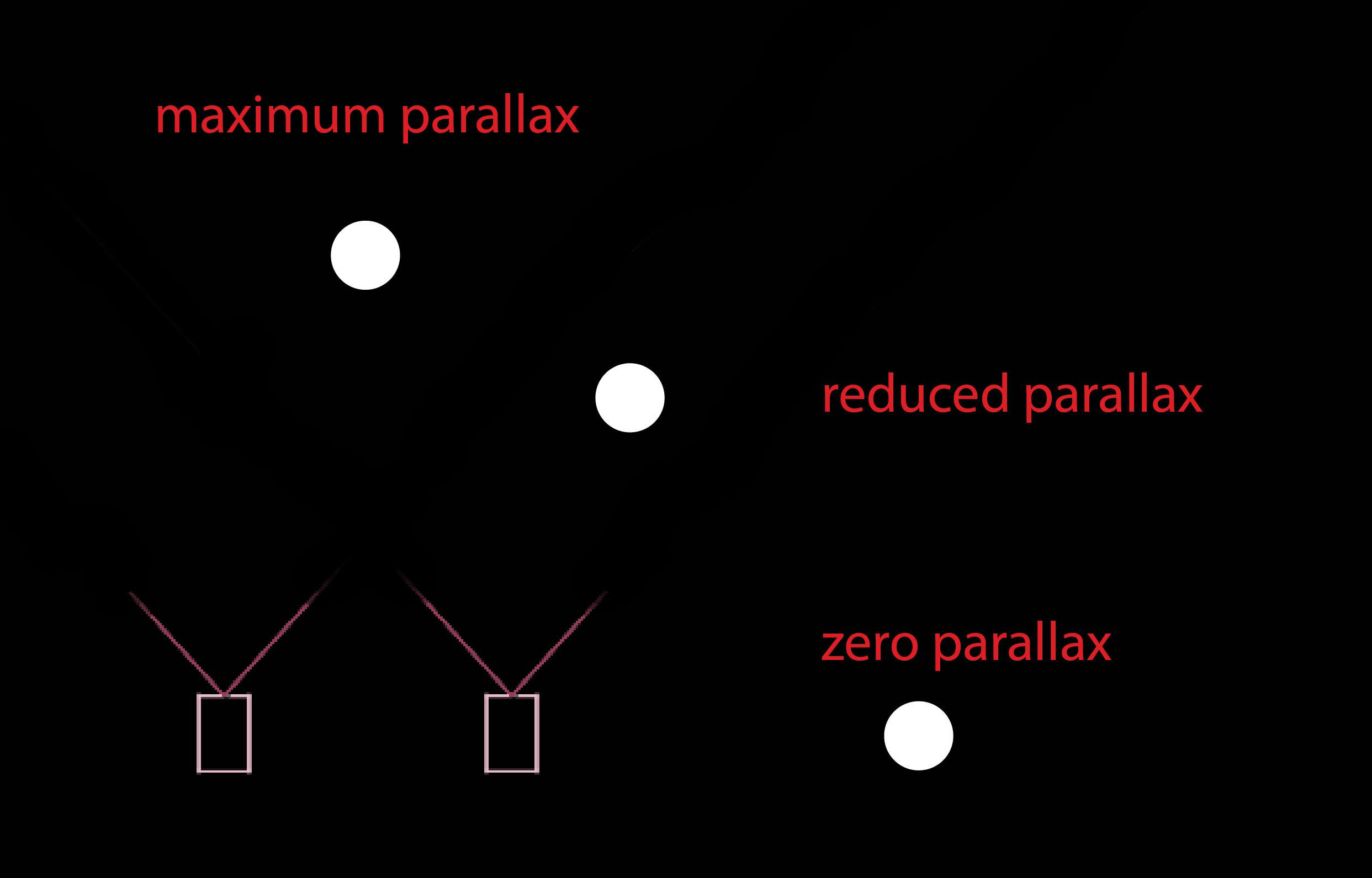
For an entire 360 array, this produces problems of consistency: for objects that are aligned between a stereo pair of cameras, you get full ’roundness’ and maximum depth. For objects at steeper angles, you get less parallax and less stereo 3D effect. So in a typical rig, you would have areas of low parallax between stereo pairs:

Weirdly, F&P’s footage shows no noticeable dropoff in stereo roundness anywhere in the image. It’s possible they’re using a ton of cameras (at the expense of more seams to stitch), or they’re hand-tweaking the stereo (that’s a lot of work), or doing something else fancy — as always, readers with actual knowledge instead of speculation are invited to share.
But back to NextVR: they’re trying to produce the same caliber of imagery without the artisans, using pure technology. It’s John Henry vs. The Machine. (For the record: I don’t know how F&P does what they do, it might be a robot army, frankly. But it’s convenient to have some contrast, so go with me here.) And NextVR intends to have full ‘stereo orthogonality,’ which basically means every pixel column should have maximum depth — it’s as though there are no blue areas of low parallax in their images, like there was a continuous array of cameras, a solid smeared-out-disk of infinitely small cameras, all edge to edge. Clearly, we’re leaving the bounds of the physical world.
The only way to do it is to revert, in a sense, to full-on CGI techniques. Which is what NextVR claims to be doing with their newly-improved tech stack: by adding light field depth sensing, they can create a world model on the fly that allows them to calculate optically impossible rigs, and serve the pixels as that impossible rig would see them. (So I’m not accused of hyperbole: I imagine it’s much simpler and faster than building a real world model, just mathematically transforming pixels in a way that would result in the same image. It’s not like the footage is being projected into a game engine, or anything.)
Heavy stuff, even if you’re not trying to do it in real time for broadcast. But there’s an interesting bonus that falls out of this approach.
“At least have the common courtesy to give me a look-around!”
To date, a big challenge for live-action VR has been lookaround — being able to serve correct pixels to a head-tracking display as the user moves right or left, forward or back, even up and down (or if you’re doing the wave while watching one of NextVR’s sports broadcasts, I guess). Trivial for CG content rendered on the fly, lookaround presents serious problems for any pre-rendered or live-action content. Even if you’re able to change the image on the fly, you’ve got to know what’s in the foreground, how much to move foreground images with parallax, and then you’ve got to have extra pixels lying around to fill in the background. That’s not really something you get from any regular camera rig — a ref or some yahoo with a big foam hat walks in front of your camera, you’re screwed: your footage is just what the camera gets, no more no less. If you’ve got time, you can hire animators to in-paint, but broadcasters don’t have time.

But NextVR’s CGI-as-live-action technique creates a full 3D map with extra pixels behind the foreground objects. Since every pixel is interpolated from the cameras and the depth metadata, you’re not limited to actual camera positions, or even positions between adjacent cameras. Because the 3D model of the environment is the scaffold for draping camera pixel data, and if you’ve got that scaffold and high quality pixels, you can start to synthesize more impossible views from other cameras that don’t exist.
So, to recap: NextVR grabs pixels (from digital cinema cameras) and depth (from light fields, and sorcery), then combines them on the fly to give you quality 3D video. In realtime. With lookaround, now.
About that sorcery.
What’s a light ray good for, anyway? (Huh, absolutely … something.)
First, a review: what NextVR is doing is not holographic in the traditional sense of the word, not at all. NextVR’s rig doesn’t capture every possible ray of light coming off the subject, record it, and transmit it to the user for final rendering. In fact, the light rays aren’t making it into the final image at all — the light field cameras are there for metadata purposes. So if a specular reflection shines into a spot between the cameras in the rig, that reflection is not captured and does not appear in the pixels. But light fields are useful for more than holography — specifically, you can use them for depth information.
There are two ways to get depth data from a light field image. One way is to just use the rays from either edge of the aperture and look at parallax. That’s how Lytro’s 3D images work, but you’re limited by the width of the aperture. (Perhaps needing more aperture-parallax is the reason for Lytro’s walnut-crushing lenses?) A much more powerful way to find depth is to digitally scan through the light field, ‘refocusing’ the whole time until a region of the image is in focus. Once a region is in sharp focus you can calculate how far away it must have been, just like reading the focus scale on a lens. (Note that this is still subject-matter dependent; a white wall doesn’t give you much information, because you only know if you’re in focus when your high frequency detail peaks … plus reflections, transparency, and translucency are your enemy.)
And that’s why it’s only part of NextVR’s approach. Because they don’t care about light field imaging for holography’s sake, they’re just looking to make images that work, today. “This isn’t an academic conversation,” observed Cole. “It’s time to execute now.” So they pair it with other technologies, trying to make a photo-realistic representation of the world, in 3D.
Lions, Tigers, and Dolphins. Oh, my.
“Really, light field is a convenient buzzword,” Cole continued, “but I don’t care if it’s time of flight, structured light, or if we have to strap a dolphin to the top of the rig.” All NextVR wants is depth information (and pixel data) so they can render a scene in stereo 3D from every possible point of view, and they’re agnostic about how they get that depth data. What exactly are these things he doesn’t care about? Let’s look at each one in turn.
Time of Flight — this means laser-time-of-flight, where a special camera sends out laser pulses, then waits to see how long it takes to bounce off the subject and return to the camera. No really, this actually works; if the pulse takes, say, 10 nanoseconds to bounce back from a given direction (that’s pretty quick, but doable for gigahertz-class electronics), your subject was about 10 feet away. (Okay, it’s not that clean — the world is metric, after all — it’s actually more like 9 feet 10 1⁄32inches, according to Google.) Some of today’s laser time of flight scanners can operate at low resolution but high rates, on the order of 100+ fps. So you get fast, fuzzy images. Awesome.
Structured Light — this is the technique Kinect, Leap Motion etc use. Just blast out some funky pattern with infrared light, and see how the subject matter distorts the pattern. You can infer the shape of what’s in front of you, just like looking at the shape a quilt makes when draped over something.

The downside to this approach is it fails, like so many other techniques, with reflectivity, transparency, smoke clouds, and super-bright sources of IR. So don’t point your Kinect directly at the sun or explosives, I guess. (That’s the best advice you’re gonna get from me, so cherish it.)
(I actually don’t know if NextVR is using structured light or not, to be honest — the light field cameras may have made this redundant if so, but I suspect they were just doing image analysis before they added light field.)
Stereo-pair Depth Maps — this is what Cole means by ‘carefully calibrated stereo rigs’ — in layman’s terms, it means looking at two images and figuring out what’s closer and what’s further away. Basically, you compare two or more images from cameras that are set apart from one another, and based on image differences you can tell how far away subjects are, because foreground objects parallax, and objects at infinity remain in the same orientation. This is how our stereo vision naturally works; to check it out, look at something near and far, then alternate winking each eye. You should see foreground objects pop back and forth, while anything further away won’t move — our stereo vision extends to about 50 feet or so. (If you’re reading this in a cubicle, definitely stand up and start winking across your open-floor-plan office. I’m not responsible for any weird looks or dates you get out of it.)

Dolphins — a reference to sonar, which is actually being used as an inexpensive distance scanner in things like cheap drones. This only works for very, very low altitudes in the drones I’ve seen, and the technology tends to suffer from poor resolution and high noise relative to the other techniques. I doubt NextVR is actually using this — unless, of course, Cole wasn’t thinking of sonar, and is instead planning to unleash a horrible dolphin-camera hybrid on the world. In which case, you heard it here first.
So the NextVR rigs apparently have all manner of crazy kit hanging off of them. But what gets done, exactly, with all that (meta-)data? I mean, they’re pitching themselves as a VR broadcast company, so whatever they’re doing they have to do fast. That’s part of the secret sauce, but that doesn’t stop us from speculating. (Nothing stops me from speculating, FYI.)
The Fast and the Spurious
All those techniques above can produce good results, but they often produce incorrect data at the same time. Look at the noise in this 3D laser scan, which is actually pretty good as these things go:

The challenge is knowing which depth-pixels are accurate, and which are noise — and knowing how accurate each input is. The bigger challenge is doing it fast; if you’re not worried about realtime, you hire a data scientist and check back in six months. If you need frame-by-frame maps in realtime, for broadcast, your options are more limited. In fact, you’re probably using a Kalman filter. Named after Rudolf Kálmán (totally still alive!), a Kalman filter takes multiple different sensor inputs and synthesizes a best guess. After being developed for the space program in the 60s, Kalman filters are now everywhere, from your phone to killer drones and NextVR camera rigs.
(A Kalman filter, as a form of sensor fusion, is analogous to how we build our sense of the world: your brain integrates your vision, inner ear, and proprioception to estimate where you are and which way is down. The simulator sickness you get from bad VR is basically this integration system failing and vomiting — the biological equivalent of a divide by zero exception.)
Now, being forced to make those estimates on the fly is the natural consequence of this tech. In a holographic capture system, you aren’t calculating anything, you’re just reporting the light rays as you captured them. But you’d need billions of light rays and an impractical number of lenses to capture a dense light field, so we may be stuck with interpolated pixels for a long, long time. That’s probably okay, though — the history of cinema is all about simulacra that are close enough to fool a willing mind. And NextVR’s simulated pixels are good enough that I had no idea they were simulated, so maybe it doesn’t matter if specular reflections cause minor problems. More importantly, it’s here today, and it looks good.
Objection, your Honor.
As always, I have to note the problems with a particular approach, and NextVR’s tech can’t be perfect. It’s somewhat subject-matter dependent, because machine-vision techniques and light field depth mapping won’t work well on highly reflective surfaces, very specular subject matter, featureless regions, etc. Repetitive patterns can cause problems too (though anyone who had the pleasure of working with the original Canon 5D mark II knows how bad moiré can look, so avoiding certain patterns is almost a reflex). But by and large the techniques complement one another.
Very large subject or camera motion could cause problems too, and anything that obscures huge swaths of the image quickly (fans throwing towels onto the lenses?) might cause problems for the algorithms … but I’m now I’m nitpicking. There may well be other issues, but I’m not privy to them and can’t imagine what they would be.
VR rigs are often put together for a specific purpose, and NextVR’s may be the best possible tech for the ‘infinite seat’ in their business plan — though it sure looks like they’re getting closer to general-purpose VR by the day.
All the World’s your (tiny) stage
Even if you have arbitrary viewpoint data, it’s not trivial to do it right, according to Cole — he repeatedly mentioned ‘having the correct world scale’ as being important. Which is ironic, because the most obvious example of incorrect world-scale I could think of was actually NextVR’s own demo footage of a fashion show: the runway models looked weirdly tiny.
At the time, I chalked this up to the width of the cameras they’re using — a Red Epic is about 100mm across, which is significantly larger than the ‘standard’ 58mm interocular. With a wider interaxial (distance between lenses), the world scale will seem smaller, like your own eyes have been blown up from 58mm apart to 100mm, or the world has shrunk by the inverse amount. But Cole confessed there was a camera rig error during that shoot, and they were stuck with choosing ‘correct world scale’ for either the audience or the models; they chose the audience because “perceptually, the models look like aliens in real life.” So the best bet for realism was to let the regular people look real, I guess.
(It’s also possible that content predates the light field tech, Cole didn’t delve into particulars.)
But if the exception proves the rule, then I believe Cole that world scale is super important. And if lookaround is a happy accident, a happier accident might require breaking that world scale. Because publishing footage for Microsoft’s HoloLens or Magic Leap’s rumored digital light field display requires re-thinking the entire presentation format. (Everything Magic Leap-related is required to be tagged ‘rumored,’ by the way, it’s federal law.) Volumetric display wasn’t originally part of NextVR’s plan, though:
“It’s somewhat unfortunate Magic Leap came along and raised the second largest series B in history,” Cole said. “It would’ve been nice to ignore them for a while.” Magic Leap, Microsoft’s Hololens — really any AR product — all present a serious problem for content creators, especially live-action content creators: how do you frame the content? As Cole said, “Where the hell do we put the basketball court? On your table?” Fortunately for NextVR, the same technology that they’re using for lookaround gives them volumetric options for free: if you’ve got the 3D map, you can represent that map as a series of voxels embedded in an AR space. So they only have to decide where to put the court, not figure out how to film everything all over again.
And Cole clearly has respect for what Magic Leap is doing, so they’ll be ready with content if Magic Leap ever comes out with their (still rumored) light field display. “If they don’t deliver,” he noted, “there will be no skid marks, they will be on the accelerator through the last dime of that money.” (FYI, that’s almost six gigadimes.)
According to Cole, in the lightning-fast VR industry “you either swing for the fences or don’t, there is no hedge.”



























{kind=link}